
티스토리 뷰
일전에 springboot base에서 File to DB Spring Batch 에 대한 예제를 포스팅했었다. 이번에는 DB to File Spring Batch에 대한 예제를 살펴보도록 하겠다.
대략적인 시나리오는 DB로부터 내용을 읽어서(JdbcCursorItemReader) 이 내용을 가공하고(Processor) File을 만들어(FlatFileItemWriter) 주는 시나리오이다. 간단한 테스트를 위해 H2 DB를 사용했으며 springboot의 version은 2.4.x이다. 그 외에 Spring Batch에 대한 기본 설정(datasource 등)은 되어 있어야 한다.
H2 DB 삽입내용
INSERT INTO `BATCH_SAMPLE_EMPLOYEE` (`USER_ID`, `USER_NAME`, `USER_GENDER`, `DEPARTMENT_CODE`) VALUES
(1, 'Kim', 'm', 'hr'),
(2, 'Janny', 'f', 'dev'),
(3, 'Billie Eilish', 'f', 'dev'),
(4, 'Taylor Swift', 'm', 'sales'),
(5, 'Jack', 'm', 'sales'),
(6, '홍길동', 'm', 'dev'),
(7, '강감찬', 'm', 'dev');DB로부터는 위와 같은 내용을 삽입한다.
SampleDb2FileChunk.java (하나의 job 단위)
import javax.sql.DataSource;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.launch.support.RunIdIncrementer;
import org.springframework.batch.item.database.JdbcCursorItemReader;
import org.springframework.batch.item.database.builder.JdbcCursorItemReaderBuilder;
import org.springframework.batch.item.file.FlatFileItemWriter;
import org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor;
import org.springframework.batch.item.file.transform.DelimitedLineAggregator;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.core.io.FileSystemResource;
import org.springframework.core.io.Resource;
import org.springframework.jdbc.core.BeanPropertyRowMapper;
import org.springframework.stereotype.Component;
import com.demo.oingdaddy.employee.chunk.processor.EmployeeProcessor;
import com.demo.oingdaddy.employee.entity.Employee;
import com.demo.oingdaddy.employee.listener.SampleJobListener;
import com.demo.oingdaddy.employee.listener.SampleStepListener;
@Component
public class SampleDb2FileChunk {
@Autowired
public JobBuilderFactory jobBuilderFactory;
@Autowired
public StepBuilderFactory stepBuilderFactory;
private Resource outputResource = new FileSystemResource("data/output/employee.txt");
@Bean
public Job sampleDb2FileChunkJob(SampleJobListener jobListener, Step sampleDb2FileChunkStep) {
return jobBuilderFactory.get("sampleDb2FileChunkJob")
.incrementer(new RunIdIncrementer())
.listener(jobListener)
.flow(sampleDb2FileChunkStep)
.end()
.build();
}
@Bean
public Step sampleDb2FileChunkStep(JdbcCursorItemReader<Employee> jdbcCursorItemReader, SampleStepListener stepListener, FlatFileItemWriter<Employee> flatFileItemWriter) {
return stepBuilderFactory.get("sampleDb2FileChunkStep")
.listener(stepListener)
.<Employee, Employee> chunk(10)
.reader(jdbcCursorItemReader)
.processor(sampleDb2FileChunkProcessor())
.writer(flatFileItemWriter)
.build();
}
@Bean
public JdbcCursorItemReader<Employee> jdbcCursorItemReader(DataSource dataSource) {
return new JdbcCursorItemReaderBuilder<Employee>()
.name("jdbcCursorItemReader")
.fetchSize(100)
.dataSource(dataSource)
.rowMapper(new BeanPropertyRowMapper<>(Employee.class))
.sql("SELECT user_id, user_name, user_gender, department_code FROM BATCH_SAMPLE_EMPLOYEE")
.build();
}
@Bean
public EmployeeProcessor sampleDb2FileChunkProcessor() {
return new EmployeeProcessor();
}
@Bean
public FlatFileItemWriter<Employee> flatFileItemWriter() {
FlatFileItemWriter<Employee> writer = new FlatFileItemWriter<>();
writer.setResource(outputResource);
writer.setAppendAllowed(true);
writer.setLineAggregator(new DelimitedLineAggregator<Employee>() {
{
setDelimiter(",");
setFieldExtractor(new BeanWrapperFieldExtractor<Employee>() {
{
setNames(new String[] { "userId", "userName", "userGender", "departmentCode" });
}
});
}
});
return writer;
}
}일단은 DB to File Chunk Batch의 전체 소스를 넣어 보았다. 위에서부터 Job, Step, Reader, Processor, Writer 순서로 구성이 되어 있다. 대략적인 그림은 다음과 같다.
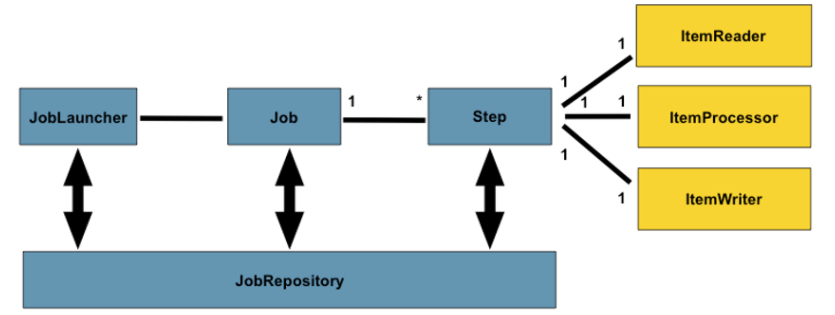
하나씩 살펴보자.
Job 정의
@Bean
public Job sampleDb2FileChunkJob(SampleJobListener jobListener, Step sampleDb2FileChunkStep) {
return jobBuilderFactory.get("sampleDb2FileChunkJob")
.incrementer(new RunIdIncrementer())
.listener(jobListener)
.flow(sampleDb2FileChunkStep)
.end()
.build();
}jobBuilderFactory를 통해 sampleDb2FileChunkJob이 실행된다. incrementer는 기본적으로 제공되는 RunIdIncrementer를 사용하며 이를 사용하는 목적은 동일한 Job의 반복 실행을 별다른 설정 없이 해주기 위함이라고 보면 된다.
그리고 이 Job은 SampleJobListener를 사용하여 Job 전후에 이벤트를 발생시키며 sampleDb2FileChunkStep 이라는 step을 사용한다.
Step 정의
@Bean
public Step sampleDb2FileChunkStep(JdbcCursorItemReader<Employee> jdbcCursorItemReader, SampleStepListener stepListener, FlatFileItemWriter<Employee> flatFileItemWriter) {
return stepBuilderFactory.get("sampleDb2FileChunkStep")
.listener(stepListener)
.<Employee, Employee> chunk(10)
.reader(jdbcCursorItemReader)
.processor(sampleDb2FileChunkProcessor())
.writer(flatFileItemWriter)
.build();
}job에서 사용하기로 한 step이다. 이건 stepBuilderFactory를 통해 실행이 되며 SampleStepListener를 사용하여 step 전후에 이벤트를 발생시킨다. 그리고 이제 chunk 가 나온다. step은 chunk 방식으로 실행할 것이며 10개 단위로 쪼개서 작업을 한다는 것이다.(commit-interval) 이 chunk는 reader, processor, writer를 가지고 있다.
Reader 정의 (JdbcCursorItemReader)
@Bean
public JdbcCursorItemReader<Employee> jdbcCursorItemReader(DataSource dataSource) {
return new JdbcCursorItemReaderBuilder<Employee>()
.name("jdbcCursorItemReader")
.fetchSize(100)
.dataSource(dataSource)
.rowMapper(new BeanPropertyRowMapper<>(Employee.class))
.sql("SELECT user_id, user_name, user_gender, department_code FROM BATCH_SAMPLE_EMPLOYEE")
.build();
}Reader는 말 그대로 읽어들이는 기능을 한다. Reader 중에서도 DB에서 Cursor 단위(여기에서는 100으로 설정)로 읽는 JdbcCursorItemReader를 사용할 것이며 설정한 datasource에서 읽는다는 것이다. sql을 통해 읽은 값을 rowMapper를 통해 Employee라는 객체에 넣어주는 역할을 한다.
Processor 정의
@Bean
public EmployeeProcessor sampleDb2FileChunkProcessor() {
return new EmployeeProcessor();
}EmployeeProcessor.java
@Slf4j
public class EmployeeProcessor implements ItemProcessor<Employee, Employee>{
public Employee process(Employee item) throws Exception {
Employee emp = item;
emp.setUserName("@" + emp.getUserName());
log.info(emp.getUserName());
return emp;
}
}Processor는 Reader에서 읽은 내용을 가공하는 역할을 하며 보통 별도의 클래스로 관리한다. Reader에서 읽은 내용을 담은 Employee의 객체는 별다른 설정을 해주지 않아도 해당 Processor에서 받아서 처리할 수 있다. DB로부터 읽어서 Employee라는 객체에 값이 들어가 있는것을 processor에서는 userName 부분을 가공하는 작업을 샘플로 만들었다.
Writer 정의 (FlatFileItemWriter)
@Bean
public FlatFileItemWriter<Employee> flatFileItemWriter() {
FlatFileItemWriter<Employee> writer = new FlatFileItemWriter<>();
writer.setResource(outputResource);
writer.setAppendAllowed(true);
writer.setLineAggregator(new DelimitedLineAggregator<Employee>() {
{
setDelimiter(",");
setFieldExtractor(new BeanWrapperFieldExtractor<Employee>() {
{
setNames(new String[] { "userId", "userName", "userGender", "departmentCode" });
}
});
}
});
return writer;
}Writer는 Processor에서 가공한 내용을 File에 넣어주는 역할을 한다. FlatFileItemWriter를 사용하고 있으며 이는 Entity에 담긴 값을 평문이 담긴 파일 형태로 내보내주는 역할을 한다. 파일을 떨굴 위치를 지정한 후 LineAggregator를 통해 구분자와 필드명에 대한 설정을 하고 write를 해준다.
배치 실행 결과 (data/output/employee.txt)
1,@Kim,m,hr
2,@Janny,f,dev
3,@Billie Eilish,f,dev
4,@Taylor Swift,m,sales
5,@Jack,m,sales
6,@홍길동,m,dev
7,@강감찬,m,dev배치를 실행하고 writer 설정 중 resource 설정하는 부분에 명시해놓은 파일이 생성되는 위치로 가서 확인을 해보면 employee.txt 파일이 생성되었을것이고 열어보면 위와 같은 내용이 담기는것을 확인할 수 있을것이다. 원래 H2 DB에 있던것에서 name 부분에 @가 붙어있는것을 확인 할 수 있다. DB로부터 잘 읽어오고 Processror가 @붙이는 작업을 잘 해줬고 이를 파일에 잘 기록했음을 확인할 수 있다.
File to DB 에 대한 내용은 아래의 포스팅을 참조하도록 하자.
[Spring Batch] Chunk Example (File to DB, Springboot based)
Spring Framework의 개발환경이 Springboot 기반으로 변함에 따라 Spring Batch의 개발방식도 이전과는 많이 달라졌다. 필자가 전에 쓴 Spring Batch에 관한 글은 Springboot 기반이 아니라서 Batch Job을 작성하..
oingdaddy.tistory.com
위에서 다룬 File to DB, DB to File을 조합하면 File to File, DB to DB에 대한 Job도 정의할 수 있을것이다.
끝!
'Framework > Batch' 카테고리의 다른 글
| [Spring Batch] Partitioner Simple Example (Springboot based) (3) | 2021.05.06 |
|---|---|
| Springboot Batch Jar 파일 생성 및 실행 (0) | 2021.03.24 |
| Spring Batch 오류시 exitCode 설정하여 Jenkins에서 실패로 인식하도록 하는 방법 (0) | 2020.11.30 |
| Spring Batch jobParameters 사용하는 방법 (with @JobScope, @StepScope) (0) | 2020.11.04 |
| [Spring Batch] Skip/Retry Simple Example (Springboot based) (0) | 2020.10.27 |