
티스토리 뷰
Spring Framework의 개발환경이 Springboot 기반으로 변함에 따라 Spring Batch의 개발방식도 이전과는 많이 달라졌다. 필자가 전에 쓴 Spring Batch에 관한 글은 Springboot 기반이 아니라서 Batch Job을 작성하면 maven build를 해서 jar로 결과물을 만들어내고 이것에 대한 실행파일을 script로 만들어서 그 script를 동작시켜 실행하곤 했다. 이런 불편함을 없애주고 설정도 간결하게 할 수 있는 Springboot 기반의 Batch가 나왔고 이제는 대세가 되었다. 따라서 이전에 작성했던 Spring Batch Chunk Example 도 Springboot 기반으로 동작시키기 위해 글을 써본다.
Springboot기반이라 많은 부분이 달라졌는데 느낀대로 나열을 해보자면 (Spring Batch vs Spring Boot Batch)
- 설정이 간결하다. 예전처럼 application-context에 jobRunner, jobRepository 등 batch 에 관련된 설정정보를 넣어주지 않아도 Springboot가 그러하듯 알아서 잘 동작한다. @EnableBatchProcessing의 힘이다.
- Springboot Batch는 Debugging이 가능하다. 이건 정말 엄청난 차이다.
- xml config 방식에서 java config 방식으로 전환이 권고된다. Springboot based가 아니라도 java config 방식으로 사용할수도 있었다. 하지만 표준은 xml config 인 느낌? (egov가 큰 역할을 하지 않았나 싶다..)
- 실행방법이 간단하다. 예전처럼 한번 실행하려면 빌드하고 각 job마다 실행 script를 작성해서 실행하곤 했는데 Springboot 기동시키는 방법으로 parameter 값만 추가해줘서 동작을 시키면 된다. IDE console에서 결과 확인이 가능해서 다른걸 열 필요가 없다.
- logging framework도 Springboot에 내장이 되어 있으므로 따로 설정하지 않아도 된다.
- Springboot의 특징이지만 엄청 빠르게 샘플 프로젝트 환경을 만들 수 있고 프로토타이핑이 가능하다. Embedded DB도 간단하게 넣을 수 있어서 편하다.
- 물론 기존의 Spring Batch 의 기능은 모두 활용할 수 있다.
이 외에도 많은 차이점이 있겠지만 일단 생각나는건 이정도라... 혹시 Spring Batch to Spring Boot Batch migration 을 생각하는 사람이 있다면 여기를 참조해서 전환을 해보도록 하자.
잡설이 길었다. 본래 글의 목적인 Springboot Batch 환경에서 Chunk 방식으로 데이터를 처리하는 방법을 알아보자.
일단 목표는 us-500.csv 라는 파일을 읽어서(Reader) 내용을 다 소문자로 변경하고(Processor) 변경한 결과값을 DB에 넣는 작업(Writer)을 하는 Chunk 방식의 Batch를 구성하는 것이다.
us-500.csv (인터넷에서 쉽게 구할 수 있음)

이런 데이터들을 담고 있는 500row짜리 csv 파일이다. 이 내용을 읽어들이기 위함이니 크게 신경쓰지 않아도 된다.
SampleChunk.java (하나의 job 단위)
import javax.sql.DataSource;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.launch.support.RunIdIncrementer;
import org.springframework.batch.item.database.BeanPropertyItemSqlParameterSourceProvider;
import org.springframework.batch.item.database.JdbcBatchItemWriter;
import org.springframework.batch.item.database.builder.JdbcBatchItemWriterBuilder;
import org.springframework.batch.item.file.FlatFileItemReader;
import org.springframework.batch.item.file.builder.FlatFileItemReaderBuilder;
import org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.ClassPathResource;
@Configuration
public class SampleChunk {
@Autowired
public JobBuilderFactory jobBuilderFactory;
@Autowired
public StepBuilderFactory stepBuilderFactory;
@Bean
public Job sampleChunkJob(SampleJobListener jobListener, Step sampleChunkStep) {
return jobBuilderFactory.get("sampleChunkJob")
.incrementer(new RunIdIncrementer())
.listener(jobListener)
.flow(sampleChunkStep)
.end()
.build();
}
@Bean
public Step sampleChunkStep(SampleStepListener stepListener, JdbcBatchItemWriter<Employee> writer) {
return stepBuilderFactory.get("sampleChunkStep")
.listener(stepListener)
.<Employee, Employee> chunk(10)
.reader(reader())
.processor(processor())
.writer(writer)
.build();
}
@Bean
public FlatFileItemReader<Employee> reader() {
return new FlatFileItemReaderBuilder<Employee>()
.name("flatFileItemReader")
.resource(new ClassPathResource("us-500.csv"))
.delimited()
.names(new String[]{"first_name", "last_name", "company_name", "address", "city", "county", "state", "zip", "phone1", "phone2", "email", "web"})
.fieldSetMapper(new BeanWrapperFieldSetMapper<Employee>() {{
setTargetType(Employee.class);
}})
.build();
}
@Bean
public EmployeeLowerProcessor processor() {
return new EmployeeLowerProcessor();
}
@Bean
public JdbcBatchItemWriter<Employee> writer(DataSource dataSource) {
return new JdbcBatchItemWriterBuilder<Employee>()
.itemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider<>())
.sql("INSERT INTO employee (first_name, last_name, company_name, address, city, county, "
+ "state, zip, phone1, phone2, email, web " +
") VALUES (:first_name, :last_name, :company_name, :address, :city, :county, "
+ ":state, :zip, :phone1, :phone2, :email, :web)")
.dataSource(dataSource)
.build();
}
}일단은 잘게 나눠서 설명을 하고 전체 파일을 안붙여 놓으면 짜증이 날수도 있으니 전체 파일을 붙여 넣어본다.
SampleChunk.java는 하나의 Batch 업무를 실행시키기 위한 모든 내용을 담고 있다.
위에서부터 하나씩 뜯어서 살펴보자.
Job 정의
@Bean
public Job sampleChunkJob(SampleJobListener jobListener, Step sampleChunkStep) {
return jobBuilderFactory.get("sampleChunkJob")
.incrementer(new RunIdIncrementer())
.listener(jobListener)
.flow(sampleChunkStep)
.end()
.build();
}jobBuilderFactory를 통해 sampleChunkJob이 실행된다. incrementer는 기본적으로 제공되는 RunIdIncrementer를 사용하며 이를 사용하는 목적은 동일한 Job의 반복 실행을 별다른 설정 없이 해주기 위함이라고 보면 된다.
그리고 이 Job은 SampleJobListener를 사용하여 Job 전후에 이벤트를 발생시키며 sampleChunkStep 이라는 step을 사용한다.
Step 정의
@Bean
public Step sampleChunkStep(SampleStepListener stepListener, JdbcBatchItemWriter<Employee> writer) {
return stepBuilderFactory.get("sampleChunkStep")
.listener(stepListener)
.<Employee, Employee> chunk(10)
.reader(reader())
.processor(processor())
.writer(writer)
.build();
}job에서 사용하기로 한 step이다. 이건 stepBuilderFactory를 통해 실행이 되며 SampleStepListener를 사용하여 step 전후에 이벤트를 발생시킨다. 그리고 이제 chunk 가 나온다. step은 chunk 방식으로 실행할 것이며 10개 단위로 쪼개서 작업을 한다는 것이다.(commit-interval) 이 chunk는 reader, processor, writer를 가지고 있다.
Reader 정의
@Bean
public FlatFileItemReader<Employee> reader() {
return new FlatFileItemReaderBuilder<Employee>()
.name("flatFileItemReader")
.resource(new ClassPathResource("us-500.csv"))
.delimited()
.names(new String[]{"first_name", "last_name", "company_name", "address", "city", "county", "state", "zip", "phone1", "phone2", "email", "web"})
.fieldSetMapper(new BeanWrapperFieldSetMapper<Employee>() {{
setTargetType(Employee.class);
}})
.build();
}Reader는 말 그대로 읽어들이는 기능을 한다. Reader 중에서도 평문을 전문적으로 읽는 FlatFileItemReader를 사용할 것이며 us-500.csv 파일을 읽는다는 것이다. 이 파일을 잘라서 Employee 라는 model의 각 컬럼에 맞게 넣어준다.
Processor 정의
@Bean
public EmployeeLowerProcessor processor() {
return new EmployeeLowerProcessor();
}Processor는 Reader에서 읽은 내용을 가공하는 역할을 하며 보통 별도의 클래스로 관리한다. Reader에서 읽은 내용을 담은 Employee의 객체는 별다른 설정을 해주지 않아도 해당 Processor에서 받아서 처리할 수 있다.
Writer 정의
@Bean
public JdbcBatchItemWriter<Employee> writer(DataSource dataSource) {
return new JdbcBatchItemWriterBuilder<Employee>()
.itemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider<>())
.sql("INSERT INTO employee (first_name, last_name, company_name, address, city, county, "
+ "state, zip, phone1, phone2, email, web " +
") VALUES (:first_name, :last_name, :company_name, :address, :city, :county, "
+ ":state, :zip, :phone1, :phone2, :email, :web)")
.dataSource(dataSource)
.build();
}Writer는 Processor에서 가공한 내용을 DB에 넣어주는 역할을 한다. 여러가지 Writer가 있지만 가장 일반적으로 사용되는 JdbcBatchItemWriter를 사용한 예제이며 이는 Employee 객체에 담긴 내용을 DB에 Write를 해준다. 직접 Query를 넣어서 해주는 방식이며 MyBatis와 연계하는 방식의 Writer도 있다. (MyBatisBatchItemWriter 는 이 글을 참조하자.)
하나의 batch 흐름을 살펴보았다.
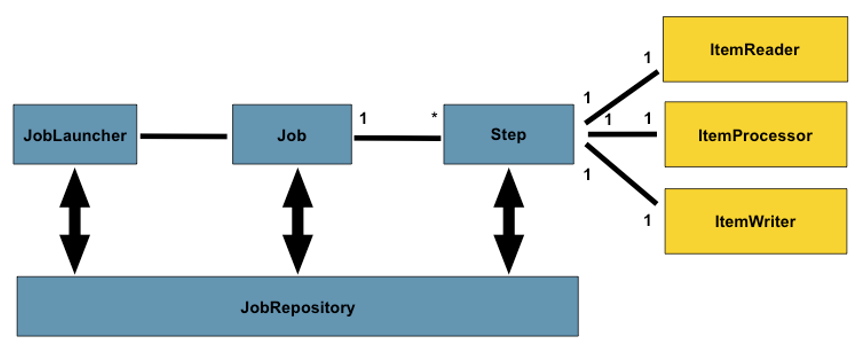
뭐 결국은 Spring Batch에서 너무나 유명한 이 그림을 기존에는 xml config 로 구성을 했다면 java config 로 구성을 한 것이다. 그게 전부다.
아래는 위의 SampleChunk.java 를 구현중에 나온 Employee.java, EmployeeLowerProcessor.java 이다.
(jobListener, stepListener 는 여기를 참조)
Employee.java
public class Employee {
private String first_name;
private String last_name;
private String company_name;
private String address;
private String city;
private String county;
private String state;
private String zip;
private String phone1;
private String phone2;
private String email;
private String web;
//getter, setter, constructure 생략csv 파일의 컬럼명과 동일하게 작성을 하였다.
EmployeeLowerProcessor.java
import org.springframework.batch.item.ItemProcessor;
public class EmployeeLowerProcessor implements ItemProcessor<Employee, Employee> {
@Override
public Employee process(final Employee employee) throws Exception {
final String first_name = employee.getFirst_name().toLowerCase();
final String last_name = employee.getLast_name().toLowerCase();
final String company_name = employee.getCompany_name().toLowerCase();
final String address = employee.getAddress().toLowerCase();
final String city = employee.getCity().toLowerCase();
final String county = employee.getCounty().toLowerCase();
final String state = employee.getState().toLowerCase();
final String zip = employee.getZip().toLowerCase();
final String phone1 = employee.getPhone1().toLowerCase();
final String phone2 = employee.getPhone2().toLowerCase();
final String email = employee.getEmail().toLowerCase();
final String web = employee.getWeb().toLowerCase();
final Employee lowerEmployee = new Employee(first_name, last_name, company_name, address, city, county, state, zip, phone1, phone2, email, web);
return lowerEmployee;
}
}이 Processor에서 해주는 역할은 csv파일로부터 읽은 데이터를 소문자로 변환을 해주는 역할을 한다. 이곳에 실질적인 business logic이 들어간다고 보면 된다.
SampleChunk 실행 결과

위의 출력 결과는 jobListener를 통해서 출력을 한 것이다. James Butt, Josephine Darakjy 이런 원래의 csv 파일을 읽어서 Processor에서 소문자화를 시킨 다음 이 값을 Writer에서 넣어준 값을 JobListener에서 조회를 하고 출력을 한 것이다. 이를 통해 정상적으로 변경된 값이 DB에 잘 들어갔음을 확인했다.
DB to File 방식에 대해 알고 싶다면 다음 글을 클릭하자!
[Spring Batch] Chunk Example (DB to File, Springboot based)
일전에 springboot base에서 File to DB Spring Batch 에 대한 예제를 포스팅했었다. 이번에는 DB to File Spring Batch에 대한 예제를 살펴보도록 하겠다. 대략적인 시나리오는 DB로부터 내용을 읽어서(JdbcCurso..
oingdaddy.tistory.com
끝!
'Framework > Batch' 카테고리의 다른 글
| [Spring Batch] Tasklet Example (Springboot based) (0) | 2020.10.26 |
|---|---|
| [Spring Batch] Listener Example (Springboot based) (0) | 2020.10.26 |
| Spring Batch 실행시 발생하는 여러가지 에러 모음 (0) | 2020.10.23 |
| Spring Batch 특정 Job만 실행하기 (2) | 2020.10.22 |
| Spring Batch Tasklet Example with StepExecutionListener (0) | 2020.07.13 |